基于HOG特征稀疏表示的非約束人臉識別方法與流程
本發明涉及一種基于HOG特征稀疏表示的非約束人臉識別方法。
背景技術:
人臉識別作為最具潛力的生物身份識別方式之一,已經深入了人類日常生活的方方面面,正確辨識出非約束環境中的人臉對和諧人機交互至關重要。但由于非約束人臉受光照、姿態、遮擋、分辨率等因素影響,因此設計出魯棒性強、效率高的非約束人臉識別方法是一項具有挑戰性的工作。
目前常用的識別方法主要分為基于手工特征提取的人臉識別和基于稀疏表示的人臉識別兩類。基于手工特征提取的人臉識別方法是針對人臉干擾因素手工選取人臉紋理特征,進而采用SVM、KNN等淺層神經網絡識別分類;基于稀疏表示的人臉識別方法是從訓練樣本中學習特征字典,測試樣本由這些特征字典原子線性表示,根據稀疏表示系數進行人臉識別。
現有技術方案的不足之處在于:
一、基于手工特征提取的人臉識別方法其關鍵是人臉特征表示,良好特征表示對算法準確性起關鍵作用,但手工選取特征是一件非常費力、啟發式的方法,能不能選取適合特征很大程度上靠經驗和運氣。對于有遮擋、姿態變化、表情變化等因素影響的非約束人臉,手工選取人臉本質特征更加困難,導致識別率大大降低。
二、基于稀疏表示的人臉識別方法可以有效增強非約束人臉識別的魯棒性,但是傳統字典是在原始人臉圖像基礎上直接構建的,字典維度高,影響算法運行效率,而且字典不能描述本質特征,冗余度高,稀疏性差。
上述問題是在人臉識別過程中應當予以考慮并解決的問題。
技術實現要素:
本發明的目的是提供一種基于HOG特征稀疏表示的非約束人臉識別方法解決現有技術中存在的手工選取人臉本質特征困難,而傳統字典是在原始人臉圖像基礎上直接構建的,字典維度高,影響算法運行效率,而且字典不能描述本質特征,冗余度高,稀疏性差的問題。
本發明的技術解決方案是:
一種基于HOG特征稀疏表示的非約束人臉識別方法,
S1、首先輸入人臉數據庫圖片,提取輸入圖片的HOG特征;
S2、從每類人中隨機選擇若干張圖片作訓練,其余留作測試,分為測試樣本和訓練樣本;將每類人每張訓練圖片的HOG特征列向量構建特征字典,字典列數與訓練樣本數目相同;
S3、利用梯度投影稀疏重建算法得到測試樣本的HOG特征稀疏表示系數;
S4、按類依次保留稀疏系數,剩余系數置零,得到近似稀疏系數,與字典相乘得到測試樣本估計值;
S5、計算測試樣本與估計值的均方誤差,根據均方誤差最小原則判斷測試樣本類別。
進一步地,步驟S1具體為:輸入原始圖像即灰度圖片I(x,y),利用HOG算子提取樣本圖片I(x,y)紋理特征,記為HOG_feature_i,HOG_feature_i數組代表第i類人的HOG特征,其中每一行又存儲了一幅圖片的紋理特征,每一行由q個特征組成。
進一步地,步驟S2具體為:從HOG_feature_i中隨機取出m行特征向量用于構建特征字典,m類似于每類人訓練樣本的個數;把從n類中抽取的m*n個特征向量轉置構建特征字典D,使得每一列代表一個訓練樣本。
進一步地,步驟S3具體為:利用梯度投影稀疏重構算法依次對HOG_feature_i中剩余的特征向量y即測試樣本的紋理特征向量進行重建,每次得到稀疏系數alpha,alpha是一個(m*n)*1的列向量。
進一步地,步驟S4具體為:依次保留稀疏系數alpha中的第1、2、3...n類對應的稀疏系數,其余類的對應系數置零,記為計算均方誤差
進一步地,步驟S5具體為:比較n個均方誤差值error_j,取其中最小的均方誤差值error_j,j的值就是該測試樣本y所屬的類別。
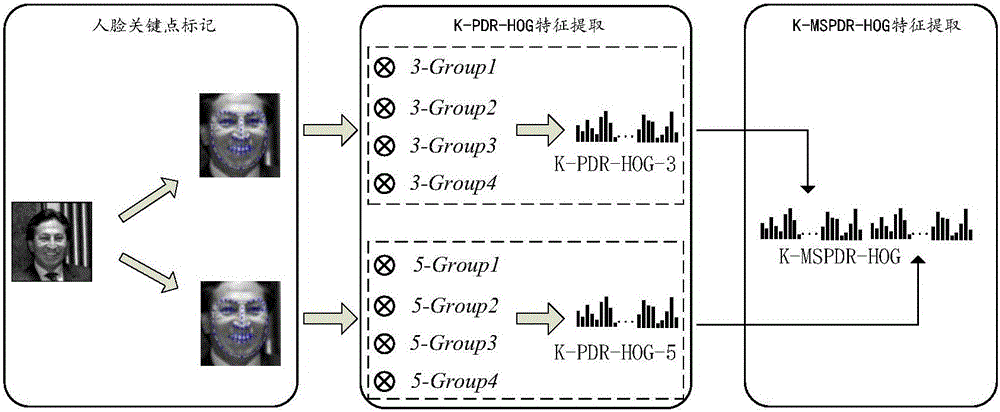
進一步地,步驟S1中,提取輸入圖片的HOG特征采用基于關鍵點的多尺度主方向旋轉HOG特征提取方法,具體為:
首先,構造多尺度主方向旋轉梯度模板,包括3*3和5*5兩個尺度的主方向旋轉梯度模板;
然后,對人臉圖像中生物視覺ROI區域即感興趣區域進行關鍵點標記,以關鍵點為中心,在鄰域范圍內分別計算3*3和5*5兩個尺度、四組旋轉梯度模板下的HOG特征,并將每個尺度的四組HOG特征級聯,得到3*3尺度、5*5尺度的主方向旋轉HOG特征,即k-PDR-HOG-3、k-PDR-HOG-5;
最后,將k-PDR-HOG-3和k-PDR-HOG-5兩個特征級聯融合,得到基于關鍵點的多尺度主方向旋轉HOG特征。
進一步地,構造3*3尺度主方向旋轉梯度模板具體為:在一個圓周2π范圍內將3*3尺度主方向梯度模板從主方向每隔45°沿逆時針旋轉一次,得到八個旋轉梯度模板,即3*3尺度主方向旋轉梯度模板;
根據梯度求導規則將八個3*3尺度主方向旋轉梯度模板兩兩為一組分為四組,其中每組旋轉梯度模板包含兩個主方向相互垂直模板。
進一步地,構造5*5尺度主方向旋轉梯度模板具體為:在一個圓周2π范圍內將5*5尺度主方向梯度模板從主方向每隔45°沿逆時針旋轉一次,得到八個旋轉梯度模板,即5*5尺度主方向旋轉梯度模板;
根據梯度求導規則將5*5尺度主方向旋轉梯度模板兩兩為一組分為四組,其中每組旋轉梯度模板包含兩個主方向相互垂直模板。
本發明的有益效果是:
一、該種基于HOG特征稀疏表示的非約束人臉識別方法,利用字典原子稀疏表示人臉特征,實現非約束人臉識別。相較傳統的基于手工特征提取的人臉識別算法,更加符合人眼視覺神經元的稀疏性特征,有效降低非約束環境對人臉識別性能的影響,增強非約束人臉識別的魯棒性。
二、本發明采用HOG特征構建字典,相比較傳統字典而言,字典原子包含了訓練圖片更豐富的邊緣紋理信息,能夠更準確描述人臉本質特征。并且HOG特征相比傳統字典維數降低,解決了傳統稀疏表示分類算法中因字典維度大導致運行速度慢的問題,有效提高算法運行效率。
三、該種基于HOG特征稀疏表示的非約束人臉識別方法,提取輸入圖片的HOG特征時可采用基于關鍵點的多尺度主方向旋轉HOG特征提取方法,能夠有效提取非約束人臉特征,相比傳統HOG算子,基于關鍵點的HOG算子的提取非約束人臉特征具有更高的準確率。
附圖說明
圖1是本發明實施例基于HOG特征稀疏表示的非約束人臉識別方法的說明示意圖。
圖2是實施例中提取輸入圖片的HOG特征的流程示意圖。
圖3是實施例中3*3尺度主方向旋轉梯度模板的示意圖。
圖4是實施例中分組3*3尺度主方向旋轉梯度模板的示意圖。
圖5是實施例中5*5尺度主方向旋轉梯度模板的示意圖。
圖6是實施例中分組5*5尺度主方向旋轉梯度模板的示意圖。
具體實施方式
下面結合附圖詳細說明本發明的優選實施例。
實施例
一種基于HOG特征稀疏表示的非約束人臉識別方法,如圖1所示。首先輸入人臉數據庫圖片,提取輸入圖片的HOG特征;從每類人中隨機選擇10張圖片作訓練,其余留作測試,分為測試樣本和訓練樣本;將每類人每張訓練圖片的HOG特征列向量構建特征字典,字典列數與訓練樣本數目相同;利用梯度投影稀疏重建算法得到測試樣本的HOG特征稀疏表示系數;按類依次保留稀疏系數,剩余系數置零,得到近似稀疏系數,與字典相乘得到測試樣本估計值;計算測試樣本與估計值的均方誤差,根據均方誤差最小原則判斷測試樣本類別。
具體為:
S1、輸入原始圖像即灰度圖片I(x,y),利用HOG算子提取樣本圖片I(x,y)紋理特征,記為HOG_feature_i(HOG_feature_i數組代表第i類人的HOG特征,其中每一行又存儲了一幅圖片的紋理特征,每一行由q個特征組成);
S2、從HOG_feature_i中隨機取出m行特征向量用于構建特征字典,m類似于每類人訓樣本的個數。把從n類中抽取的m*n個特征向量轉置構建特征字典D,使得每一列代表一個訓練樣本;
S3、利用梯度投影稀疏重構算法依次對HOG_feature_i中剩余的特征向量y即測試樣本的紋理特征向量進行重建,每次得到稀疏系數alpha,alpha是一個(m*n)*1的列向量,因為測試樣本y是一個q*1的列向量,特征字典D是一個q*(m*n)的矩陣,且y=D*alpha;
S4、依次保留alpha的第1、2、3...n類對應的稀疏系數,其余類的對應系數置零,記為計算均方誤差
S5、比較n個error_j值,取其中最小的error_j值。j的值就是該測試樣本y所屬的類別。
步驟S1中,提取輸入圖片的HOG特征優選采用基于關鍵點的多尺度主方向旋轉HOG特征提取方法,具體為:
首先,構造多尺度主方向旋轉梯度模板,包括3*3和5*5兩個尺度的主方向旋轉梯度模板;
然后,對人臉圖像中生物視覺ROI區域即感興趣區域進行關鍵點標記,以關鍵點為中心,在鄰域范圍內分別計算3*3和5*5兩個尺度、四組旋轉梯度模板下的HOG特征,并將每個尺度的四組HOG特征級聯,得到3*3尺度、5*5尺度的主方向旋轉HOG特征,即k-PDR-HOG-3、k-PDR-HOG-5;
最后,將k-PDR-HOG-3和k-PDR-HOG-5兩個特征級聯融合,得到基于關鍵點的多尺度主方向旋轉HOG特征。
步驟S1對原始HOG算子進行改進,構建了3*3、5*5兩個尺度主方向旋轉HOG算子,實現了非約束環境下有效人臉特征提取。一方面,相比原始HOG梯度模板,改進梯度模板范圍變大,包含的像素點個數增加,從多尺度角度捕捉人臉紋理灰度變化統計信息;另一方面,改進梯度模板主方向在0°~360°范圍內每隔45°逆時針旋轉一次,得到八個旋轉梯度模板,根據梯度求導規則將八個模板分為四組(Group),分別計算關鍵點鄰域范圍內的梯度方向直方圖,從多方向角度描述人臉紋理方向變化統計信息。
步驟S1的具體實現流程如圖2所示:首先對人臉圖像進行關鍵點標記,然后以關鍵點為中心,在一定鄰域范圍內分別提取3*3尺度、5*5尺度的主方向旋轉HOG特征,得到基于關鍵點的3*3尺度主方向旋轉HOG特征(3*3-Scale Principal Direction Rotation Histograms of Oriented Gradient based on keypoints,k-PDR-HOG-3)和基于關鍵點的5*5尺度主方向旋轉HOG特征(5*5-Scale Principal Direction Rotation Histograms of Oriented Gradient based on keypoints,k-PDR-HOG-5),然后將這兩個特征進行級聯融合,得到最終的基于關鍵點的多尺度主方向旋轉HOG特征(Multi-Scale Principal Direction Rotation Histograms of Oriented Gradient based on keypoints,k-MSPDR-HOG)。
3*3尺度主方向旋轉梯度模板:利用傳統的[-101]梯度模板計算梯度幅值和方向存在較大的局限性。首先,傳統梯度模板僅考慮中心像素點周圍4個像素點,包含的像素點灰度信息較少,不能豐富地體現中心像素點周圍的紋理信息;其次,傳統梯度算子僅計算水平和豎直兩個方向的紋理變化,但是因為人臉五官的形狀較為規律,人臉的主要幾個組成部分,如眉毛,眼睛,鼻子和嘴,它們的中心部分均是水平或垂直延長的,但是它們的尾部均是大約在對角線方向(π/4和3π/4)收斂,僅從水平和豎直兩個方向計算梯度幅值和梯度方向不足以體現人臉紋理信息的變化。受以上傳統梯度模板局限性的啟發,實施例構建了如下所示的3*3尺度主方向梯度模板,模板中權值2大于其他數值,設為主方向,如箭頭所示。
在一個圓周2π范圍內將模板主方向每隔45°沿逆時針旋轉一次,得到八個旋轉梯度模板,即3*3尺度主方向旋轉梯度模板,如圖3所示。并根據梯度求導規則將八個模板分為四組(Group),如圖4所示,其中mxi和myi分別表示兩個主方向相互垂直模板,便于計算不同方向的梯度幅值和梯度方向及統計HOG特征。相比傳統[-101]梯度模板,3*3主方向旋轉梯度模板計算中心像素點周圍8*2=16個像素點灰度值,而傳統[-101]梯度模板僅計算中心像素點周圍2*2=4個像素點灰度值,統計像素點個數增加,可以捕捉到的人臉紋理灰度變化信息也增加;同時3*3主方向旋轉梯度模板在0、π/4、π/2、3π/4、π、5π/4、3π/2、7π/4、2π方向上增加模板的權重,突出主方向的灰度變化情況,描述主要的人臉紋理延伸方向,并且將其分為四組,分別用來提取不同方向的HOG特征,可以更充分描述豐富的人臉紋理方向信息。
5*5尺度主方向旋轉梯度算子:考慮不同尺度的梯度算子表征的人臉紋理信息不同,因此,本發明在3*3尺度主方向旋轉梯度模板基礎上,進一步構造5*5尺度主方向旋轉梯度模板,并與3*3尺度主方向旋轉梯度模板結合使用,使其表征的非約束人臉信息更加全面豐富。5*5主方向梯度模板如下:
同理,在一個圓周(2π)范圍內將模板主方向每隔45°沿逆時針旋轉一次,得到八個旋轉梯度模板,即5*5尺度主方向旋轉梯度模板,如圖5所示。并根據梯度求導規則將八個模板分為四組(Group),如圖6所示。
在實施例中,一幅人臉圖像標記51個關鍵點,分別標識人臉中眼睛、嘴巴、眉毛等關鍵特征區域。每個關鍵點的梯度方向直方圖為9維,并且本發明從兩個尺度八個方向全面充分描述非約束人臉特征,因此,最終的k-MSPDR-HOG特征維度為51*9*4*2=3672,特征信息更全面豐富,噪聲魯棒性更強。
傳統的HOG算法中用[-101]梯度模板計算像素點的梯度幅值和梯度方向,它僅描述了水平和垂直兩個方向的灰度變化,且包含的像素點信息較少,應用于非約束人臉特征提取效果較差。因此實施例提出的基于關鍵點的多尺度主方向旋轉HOG算子(Multi-Scale Principal Direction Rotation Histograms of Oriented Gradient based on keypoints,k-MSPDR-HOG)可以有效提取非約束人臉特征。一方面,實施例是基于面部關鍵點提取特征,可以有效消除非約束全局人臉特征提取中光照、姿態、旋轉等干擾因素影響,相比傳統HOG算子,基于關鍵點的HOG算子(HOG based on keypoints,k-HOG)提取非約束人臉特征準確率提高了20.37%(LFW數據庫)和5.5%(ORL數據庫);另一方面,實施例以關鍵點為中心,在一定鄰域范圍內從多尺度、多方向兩個角度充分描述非約束人臉特征,相比k-HOG算子,k-MSPDR-HOG算子提取非約束人臉特征準確率又進一步提高了11.66%(LFW數據庫)和6.68%(ORL數據庫)。由此可見,實施例提出的基于關鍵點的多尺度主方向旋轉HOG特征提取方法是一種有效的非約束環境下的人臉特征提取算法。
實驗驗證
所有實驗均采用相同的人臉數據庫LFW-GBVS數據庫進行仿真,即LFW數據庫經過基于視覺顯著性的人臉目標檢測算法處理所得。從中選出前10類人,按名稱排序,作為樣本,共344張圖片,每張圖片歸一化為128*128像素大小。隨機抽取樣本中每類人的10張圖片作為訓練樣本用于構建特征字典,每類人剩下的圖片作為測試樣本。仿真結果如下:
實施例與基于HOG、LBP、Gabor手工特征算子的人臉識別方法性能比較如下:
HOG、LBP和Gabor算子均用來提取人臉特征,不同特征算子的參數設置如下:
基于HOG算子的人臉識別方法具體參數設置為:先把一幅128*128(pixels)圖片劃分為64個16*16(pixels)的block,每個block劃分成2*2個cell;計算每個cell中每個像素點的梯度方向和梯度幅值,將這些梯度方向劃分為9個區間,得到一個cell的梯度方向直方圖,把4個cell的梯度方向直方圖連接起來得到一個block的梯度方向直方圖,最后把所有block的梯度方向直方圖連接起來,得到這幅圖片的HOG特征;最后把HOG特征輸入到SVM進行分類識別。
基于LBP算子的人臉識別方法具體參數設置為:先把一幅128*128(pixels)圖片分成16個32*32(pixels)block,分別計算每個block的二進制編碼值,然后把所有block的特征級聯在一起得到圖片的LBP特征,最后把LBP特征輸入到SVM進行分類識別。
基于Gabor算子的人臉識別方法是提取每幅圖片4個尺度6個方向的Gabor特征,再對這24個紋理特征圖進行下采樣降維,然后按照尺度、方向的順序把系數矩陣排成列向量得到這幅圖片的Gabor特征;最后把歸一化的樣本特征輸入到SVM進行分類識別。
實施例與基于HOG、LBP、Gabor算子的人臉識別方法的性能比較如表1所示。
表1實施例與基于HOG、LBP、Gabor手工特征算子的人臉識別方法的性能比較
從表1可以看出,采用實施例的非約束人臉識別率最高,因為實施例算法可以適當的克服非約束環境對人臉識別性能的影響,具有更好的魯棒性能。HOG算子是一種有效的邊緣特征描述子,但是忽略了局部特征之間的空間排列信息,因此識別率略低于實施例;傳統的LBP算子是一種有效的紋理特征描述子,缺點是LBP算子只覆蓋了固定半徑范圍內的小區域,不能滿足不同尺寸和頻率紋理的需要,因此識別率較低;Gabor算子雖然是常用的特征提取算子,但是識別率也沒有實施例的識別率高。
實施例與基于其他字典學習稀疏表示的人臉識別算法性能比較如下:
基于原圖字典學習的稀疏表示人臉識別算法(Original_SRC)的字典構建是先把二維樣本圖片下采樣轉換成一維列向量(1024*1),再隨機選取一些向量構造字典,然后按照SRC算法進行識別分類。
基于ICA字典學習的稀疏表示人臉識別算法(ICA_SRC)字典構建方法:對每類人的訓練樣本圖片隨機取300個16*16的patch,把每個patch轉換成256*1的列向量就形成了256*300的矩陣,把這個矩陣作為ICA的輸入,得到這類人的獨立成分分量256*300作為字典,按照同樣的方法對樣本中其他類人提取ICA特征,最后把得到的10類人的字典級聯在一起,構成一個大字典。
基于Shearlet字典學習的稀疏表示人臉識別算法(Shearlet_SRC)字典構建方法:對樣本圖片進行非下采樣Shearlet變換得到剪切波系數,選取高頻分量每個尺度每個方向的系數的最大值作為高頻分量的表征,對低頻與高頻的特征進行相加融合,最后通過取局部最大降低系數維度,用降維后的剪切波系數構造字典。
基于K-SVD字典學習的稀疏表示人臉識別算法(K-SVD_SRC)用K-SVD算法對訓練樣本進行訓練得到字典。
表2實施例與其他基于字典學習的稀疏表示人臉識別算法的性能比較
從表2可以看出,采用實施例人臉識別算法的識別率最高而且識別時間最短;Original_SRC方法沒有對原圖像特征進行篩選而直接用原圖像素值構造字典,字典原子不能稀疏地表示測試圖片,只有67.6%的識別率,且識別時間較長;ICA_SRC方法采用學習訓練圖片的獨立分量的方法構建字典,每類人的字典都是冗余的,雖然也得到了理想的識別率,但是此方法是以犧牲大量時間為代價;Shearlet_SRC方法采用訓練樣本的剪切波系數構建字典,其中降維會導致圖像的部分方向和尺度信息丟失,因此識別率只有63%;K-SVD_SRC方法使用K-SVD方法從訓練樣本中學習字典,得到的冗余字典是訓練樣本的稀疏表示,再用這個字典進行稀疏表示分類可以得到70.9%的識別率,高于除實施例之外的其他SRC方法。
- 還沒有人留言評論。精彩留言會獲得點贊!